Big IP F5 Load Balancing Basic Concetps
Load Balancing
Load balancing
technology is the basis on which today’s Application Delivery
Controllers operate. But the pervasiveness of load balancing technology
does not mean it is universally understood, nor is it
typically considered from anything other than a basic, networkc
entric viewpoint. To maximize its benefits, organizations should
understand both the basics and nuances of load balancing.
By end of this Blog Session you will understand following topics.
- Introduction
- Basic Load Balancing Terminology
- Node, Host, Member, and Server
- Pool, Cluster, and Farm
- Virtual Server
- Putting It All Together
- Packet Flow Diagram
- Load Balancing Basics
- Traffic Distribution Methods
- NAT Functionality
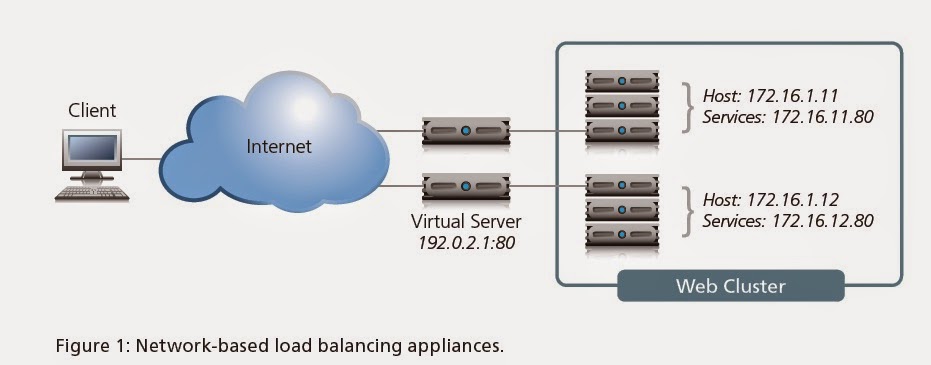
Basic Load Balancing Terminology
Node, Host, Member, and Server
Node, Host -> Physical Server -> Ex 172.16.5.1
Member -> This is referred as service which has combination of IP address and port
Ex: 172.16.5.1:80
Server : Virtual Server (F5 Load balancer)
Pool, Cluster, and Farm
Load balancing allows organizations to distribute inbound traffic across multiple
back-end destinations. It is therefore a necessity to have the concept of a collection
of back-end destinations. Clusters, as we will refer to them herein, although also known as pools or farms, are collections of similar services available on any number of hosts. For instance, all services that offer the company web page would be collected into a cluster called “company web page” and all services that offer e-commerce services would be collected into a cluster called “e-commerce.”
VIRTUAL SERVER:
Virtual server uses single IP address to
represent the server and listening service. Virtual server listens for the
connections initiated by the client, once it received first packet from the
client it translates the destination address from the virtual address to the
node address. The choice of the node is based on the load balancing or
persistence.
Putting It All Together

Packet Flow Diagram


Load Balancing Basics
With this common
vocabulary established, let’s examine the basic load balancing
transaction. As depicted, the load balancer will typically sit in-line
between the client and the hosts that provide the services the client
wants to use. As with most things in load balancing, this is not a rule,
but more of a best practice in a typical deployment. Let’s also assume
that the load balancer is already configured with a virtual server that
points to a cluster consisting of two service points. In this deployment
scenario, it is common for the hosts to have a return route that points
back to the load balancer so that return traffic will be processed
through it on its way back to the client.
The basic load balancing transaction is as follows:
1. The client attempts to connect with the service on the load balancer.
2. The load balancer accepts the connection, and after deciding which host
should receive the connection, changes the destination IP (and possibly port)
to match the service of the selected host (note that the source IP of the client
is not touched).
3. The host accepts the connection and responds back to the original source,
the client, via its default route, the load balancer.
4. The load balancer intercepts the return packet from the host and now changes
the source IP (and possible port) to match the virtual server IP and port, and
forwards the packet back to the client.
5. The client receives the return packet, believing that it came from the virtual
server, and continues the process.
Traffic Distribution methods :
STATIC METHOD:
Ø Round Robin: Client Requests been distributed evenly
across the available servers in the 1:1 ratio.
Ø Ratio:
The ration method distributes the load across available members in the given
proportion. (e.g) if the given proportion is 3:2:1:1 then first server will
receive the 3 packets and 2nd server will receive 2 packets and
other 2 servers will receive one packet to process.
DYNAMIC METHOD:
Fastest:
Load will
be shared across the members based on the response time. The response time has
been computed every second based on the monitoring response time and packet
response time.
Least Connections:
The least
connection mode distributes the load to the members, which has the least connection to process.
Observed:
The
observed load balancing will work based on the system performance. Performance
is the combination of the system response time and the connection count on the
system.
Predictive:
Predictive
is as similar as how observed method. Since the observed method using the
system performance of the current time, predictive method calculates the current load and the before second load.
NAT FUNCTIONALITY:
BIG-IP using NAT in three ways, following
Ø Virtual
Server
Ø Network
Address Translation
Ø Secure
Network Address Translation
VIRTUAL SERVER:
Virtual server uses single IP address to
represent the server and listening service. Virtual server listens for the
connections initiated by the client, once it received first packet from the
client it translates the destination address from the virtual address to the
node address. The choice of the node is based on the load balancing or
persistence.
SNAT:
Unlike virtual servers, SNAT never listen
for connections initiated to the SNAT address. Here when BIG-IP sees the
connection every time it translates the source address from the allowed host
address.
iRules:
iRules is the script which influences the
traffic which flows through the BIG-IP if the script matches for the traffic.
Commonly iRules are used to select the pool to process a client request. This
is technically called as a UNIVERSAL
INSPECTION ENGINE (UIE).
The Load Balancing Decision
Usually at this point, two questions arise: how does the load balancer decide which
host to send the connection to? And what happens if the selected host isn’t working?
Let’s discuss the second question first. What happens if the selected host isn’t
working? The simple answer is that it doesn’t respond to the client request and the
connection attempt eventually times out and fails. This is obviously not a preferred
circumstance, as it doesn’t ensure high availability. That’s why most load balancing
technology includes some level of health monitoring that determines whether a host
is actually available before attempting to send connections to it.
There are multiple levels of health monitoring, each with increasing granularity and focus. A basic monitor would simply PING the host itself. If the host does not respond to PING, it is a good assumption that any services defined on the host are probably down and should be removed from the cluster of available services. Unfortunately, even if the host responds to PING, it doesn’t necessarily mean the service itself is working. Therefore most devices can do “service PINGs” of some kind, ranging from simple TCP connections all the way to interacting with the application via a scripted or intelligent interaction. These higher-level health monitors not only provide greater confidence in the availability of the actual services (as opposed to the host), but they also allow the load balancer to differentiate between multiple services on a single host. The load balancer understands that while one service might be unavailable, other services on the same host might be working just fine and should still be considered as valid destinations for user traffic.
This brings us back to the first question: How does the load balancer decide which host to send a connection request to? Each virtual server has a specific dedicated cluster of services (listing the hosts that offer that service) which makes up the list of possibilities. Additionally, the health monitoring modifies that list to make a list of “currently available” hosts that provide the indicated service. It is this modified list from which the load balancer chooses the host that will receive a new connection. Deciding the exact host depends on the load balancing algorithm associated with that particular cluster. The most common is simple round-robin where the load balancer simply goes down the list starting at the top and allocates each new connection to the next host; when it reaches the bottom of the list, it simply starts again at the top. While this is simple and very predictable, it assumes that all connections will have a similar load and duration on the back-end host, which is not always true. More advanced algorithms use things like current-connection counts, host utilization, and even real-world response times for existing traffic to the host in order to pick the most appropriate host from the available cluster services. Sufficiently advanced load balancing systems will also be able to synthesize health monitoring information with load balancing algorithms to include an understanding of service dependency. This is the case when a single host has multiple services, all of which are necessary to complete the user’s request. A common example
would be in e-commerce situations where a single host will provide both standard HTTP services (port 80) as well as HTTPS (SSL/TLS at port 443). In many of these circumstances, you don’t want a user going to a host that has one service operational, but not the other. In other words, if the HTTPS services should fail on a host, you also want that host’s HTTP service to be taken out of the cluster list of available services. This functionality is increasingly important as HTTP-like services become more differentiated with XML and scripting.


No comments:
Post a Comment